
SP²Bench Generator and DBLP RDF Data
The SP²Bench Data Generator
The data generator supports the generation of arbitrarily large DBLP-like data in NTriples syntax. It supports data generation up to a given triple count (parameter -t <TRIPLE COUNT>) or up to a given file size (parameter -s <SIZE IN KB>). Data generation is incremental, deterministic and platform independent. In particular, smaller documents are always contained in larger documents, and each two runs with identical parameters always give the same result, even on different machines and operating systems (we use fixed seeds for the random parts of the algorithm). Our data generator is both performant and scalable, for instance we were able to generate a 3 Billion triple RDF document (~300GB of data) on a standard Desktop PC (i.e., an Intel Core2 Duo E6400 2.13GHz CPU with 3GB DDR2 667 MHz nonECC physical memory) in about 12 hours, with a peak memory consumption of 1.2GB. Binaries and source code of our data generator are available for download at our download page.
Structure of the Generated Data
The DBLP database contains bibliographic about the field of Computer Science and, in particular, databases. The original database is publicly available in XML format. A mapping from the DBLP XML database to RDF has been implemented in the D2R Server. To be close to an existing scenario, we basically follow the latter translation scheme. However, as we want to generate arbitrarily large documents, we do not translate the database, but instead provide lists of names and other keywords to our data generator.
Our generator mirrors vital key characteristics of the existing DBLP bibliography, thus combining the benefits of both a real-world scenario, i.e. data with real-world characteristics, and the possibility to generate arbitrarily large RDF documents. Among others, we mirror the structure of document classes (such as articles, journals, proceedings, inproceedings, etc.), relations between document classes (e.g. between inproceeding and proceedings), characteristics of authors and coauthors, and parts of the citation system. Below, we show a sample instance of the generated data.
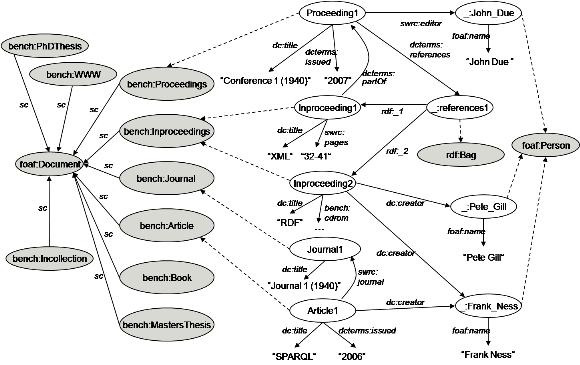
On the logical level, we distinguish between the schema layer (gray) and the instance layer (white). Reference lists are modeled as blank nodes of type rdf:Bag, i.e. using standard RDF containers (see node :references1). Authors and editors are represented by blank nodes of type foaf:Person. Class foaf:Document splits up into the individual document subclasses bench:Journal, bench:Article, bench:Proceedings, bench:Inproceedings, bench:Incollection, bench:Book, bench:WWW, bench:MastersThesis, and bench:PhDThesis (sc denotes rdfs:subClassOf). The RDF graph above defines three persons, one proceeding, two inproceedings, one journal, and one article. For readability reasons, we plot only selected predicates. As also illustrated, property dcterms:partOf links inproceedings and proceedings together, while swrc:journal connects articles to the journals they appeared in.
In order to provide an entry point for queries that access authors and to provide a person with fixed characteristics, we created a special author, named after the famous mathematician Paul Erdoes. Paul Erdoes is modeled by a fixed URI. As an example query consider Q8, which extracts all persons with Erdoes Number 1 or 2. We emphasize that our data generator creates RDF data with many characteristics. For instance, the generated data contains blank nodes (i.e. the authors), containers (i.e. references are modeled using the RDF standard container class rdf:Bag), long strings (i.e. abstracts), and so on.
The profound understanding of the data and its characteristics facilitates the understanding of the benchmark queries. Consider for instance query Q3(a), (b), and (c). From the analysis of the DBLP dataset we know that articles have properties swrc:pages, swrc:month, and swrc:isbn with probabilities 92.61%, 0.65%, and 0%, respectively. Hence, Q3(a) is much less selective than Q3(b), and Q3(c) always returns the empty result. In fact, this query has been designed to test the impact of indices on query processing, and statistics might be used to speed up query processing in this scenario. If you are interested in additional material, please contact us and we will send you more information on data characteristics.
[ Back to the SP²Bench Main Page ]